PostgreSQL
- PostgreSQL
概要
- この Log では、PostgreSQL の内部アーキテクチャを勉強する際に調査したことを残す。
- 調べたい概念などをドキュメントやブログ記事をもとに調査を発散させた後に、この記事にその内容をまとめる。
Outline
PostgreSQL を利用できる環境の構築方法について教えてください。
- Docker + docker-compose を用いた構築方法
- AWS CLI + RDS for PostgreSQL を用いた構築方法
- AWS CLI + Aurora PostgreSQL を用いた構築方法
RDBMS あるいは PostgreSQL のアーキテクチャについて詳しくなるために読んでいる本や資料について教えてください。
MySQL のストレージエンジン InnoDB に関する記事 (ストレージエンジンの話 ~InnoDBのredo logをざっくり理解する~) を読んで学んだことを教えてください。
InnoDB における MVCC のガベージコレクションに関する記事 (InnoDBのMVCCのガベージコレクションについて) を読んで学んだことを教えてください。
WAL がディスクに吐き出されるタイミングについて教えてください。
- WAL バッファがディスクに保存されるまでに DB がクラッシュすると WAL バッファは消えてしまいます。この際、直前の書き込みまでのロールバックが物理的に不可能になる気がするのですが、これは正しいでしょうか?また、正しければ、このような状況になったとするとどのようにデータの復旧を行えば良いですか?
BTree を C 言語で実装してください。
B+Tree を C 言語で実装してください。
カバリングインデックスとそれ以外で検索時間が本当に変わるかを確認してみてください。
気合を入れてこの連載 (DBアタマアカデミー) を全て読んでください。
OSS-DB道場 を一通り読んでください。
気になるポスグレのコンポーネントについて調査してください。
ポスグレのパーティションを手元で検証し、メリットデメリットを考えてみてください。
The Internals of PostgreSQL を最初から読んで特にソースコードを読みたい箇所がないか調査してみてください。
リリースノートから追加された機能の中から気になるものを見つけて、commit id からメーリスや追加された実装を確認してみてください。
write システムコールと read システムコールと O_DIRECT について教えてください.
ファイルシステムに関して教えてください。
fsync システムコールについて教えてください。また、簡単なサンプルプログラムも実装してください。
fsync システムコールとポスグレとの関係性について教えてください。
Linux Kernel における inode に関して詳しく教えてください。
MySQL における redlo log に関して教えてください。
ページって何ですか。教えてください。
pgbench のチュートリアルを試して見てください。
EXPLAIN コマンドを使って実行計画を確認してみてください。
WAL Log と Archive Log の違いはなんですか?
物理レプリケーションと論理レプリケーションの違いを教えて下さい。
- 物理レプリケーション -> ストリーミングレプリケーション (Streaming)
- 論理レプリケーション -> ロジカルレプリケーション (Logical)
WAL Sender について教えてください。
Lock の全てのレベルについて説明してください。
ポスグレのページに関して教えてください。
PostgreSQL を利用できる環境の構築方法について教えてください。
RDS for PostgreSQL や Aurora PostgreSQL を使用しても良いが、起動に時間がかかってしまう。待ち時間を減らして、サクッと検証したい時は参考情報 [1] をもとに Docker + docker-compose を使用する。
使用する docker-comopose.yaml
version: '3'
services:
db:
image: postgres:14
container_name: postgres
ports:
- 5432:5432
volumes:
- db-store:/var/lib/postgresql/data
environment:
- POSTGRES_PASSWORD=passw0rd
volumes:
db-store:
- 起動して、PostgreSQL に接続するコマンドを以下に示す。
docker-compose up -d
docker exec -it postgres bash
psql -h localhost -U postgres
参考情報
RDBMS あるいは PostgreSQL のアーキテクチャについて詳しくなるために読んでいる本や資料について教えてください。
- [改訂新版]内部構造から学ぶPostgreSQL 設計・運用計画の鉄則
ポスグレの主なファイル群について教えてください。
- 主に、3 つのファイルがある。
- データファイル
- Index ファイル
- WAL ファイル
- pg_xlog ディレクトリに WAL ファイルは配置され、16 MB の固定サイズで作成される。
- xlog は、Transaction Log のことを指してる?
- 大量の tx 処理があると xlog も増えるので、バッチ処理を行う場合にはその点に気をつけて WAL を破棄するタイミングを設定しないといけない。
補足
MySQL ではトランザクションのことを trx と略すが、ポスグレでは tx と略すっぽい。
TOAST について教えてください。
TOAST とは、The Over-sized Attribute Storage Technique の頭文字を取った略称のことで、日本語では過大属性格納技法と呼ばれる。
非常に長い (大きい) データをポスグレの固定帳の 8KB のページに収めるための手法である。
OID (Object ID)
CHECKPOINT とはトランザクションログのチェックポイントを強制的に実行するコマンドのことである。
MySQL のストレージエンジン InnoDB に関する記事 (ストレージエンジンの話 ~InnoDBのredo logをざっくり理解する~) を読んで学んだことを教えてください。
データベースがどのように原子性を実現しているかを解説した記事となっている。
この記事を読んでいるとファイルシステムとか inode が気になり、以下の段落で調査をしていた。
やっと戻ってきた …
ファイルシステムと write システムコールや fsync システムコールの関係性について教えてください。
ストレージエンジンの話 ~InnoDBのredo logをざっくり理解する~ の記事を読んでいると、fsync システムコールに関する話が少し出ていた。このシステムコールが少し気になったので、参考記事をもとに詳しく調べてみた。参考にした記事は以下である。(すごいわかりやすくて良い記事やった :))
上の記事 (1. ファイルシステムについてざっくり理解する) を読みつつ他の記事も参考にしてファイルシステムや inode 周りについて調査していた。
ユーザ空間やファイルシステム、そしてストレージデバイスなどの構成はざっくり以下のようになっている。(参考 : 知っておきたいLinuxファイルシステムの概念)
- User Space <-> System Call Interface <-> VFS <-> File System <-> Buffer Cache <-> Device Driver <-> Disk Controller の構成をしている。
VFS 自体は、ファイルシステムの差分を吸収するレイヤーとなっている。ファイルシステムを VFS で抽象化することで、統一インターフェースで操作が可能となる。
ファイルシステムには ext4 や Btrfs などがある。(参考 : ファイルシステム)
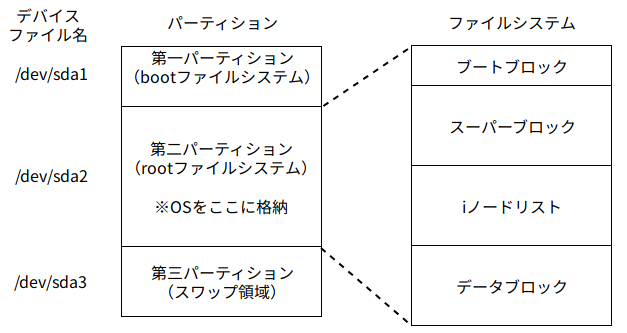
ファイルシステムの構造に関してはこの記事 (Linuxのブートとファイルシステムについて) の以下の図が参考になった。
- Ubuntu 18.04 を使っているとたまに目にしていた /dev/sda1 が boot ファイルシステムとなっていることに初めて気づいた。(結構びっくりした。)
- /dev/sda1 : 第一パーティション (boot ファイルシステム)
- /dev/sda2 : 第二パーティション (root ファイルシステムで OS が格納されている。)
- ブートブロック : 常に先頭に位置し、OS を起動するための情報を保存する。
- スーパーブロック : ファイルシステムの大きさ、空きブロックに関する情報、i ノードに関する情報、スーパーブロックが修正されたことを示すフラグなどが格納されている。
- i ノードリスト
- データブロック
- /dev/sda3 : 第三パーティション (スワップ領域)
- Ubuntu 18.04 を使っているとたまに目にしていた /dev/sda1 が boot ファイルシステムとなっていることに初めて気づいた。(結構びっくりした。)
ジャーナリングに関して (上の参考に関連して)
- 後々にジャーナリングも出てくるので、ここでも確認しておく。
- この記事 (ファイルシステム) には
ジャーナリングに関する記述もある。exFAT, ext2, FAT16/32, Reiser4 (オプション), Btrfs, ZFS を除く上記のすべてのファイルシステムは ジャーナリング を使用しています。ジャーナリングは、ファイルシステムにコミットする前に変更を記録することで、障害からの回復力を提供します。システムクラッシュや停電の際、このようなファイルシステムはオンラインに戻すのが速く、破損する可能性も低くなります。ロギングはファイルシステムの専用領域で行われます。
- この記事 (ジャーナリングファイルシステム) も参考になった。
ジャーナリングファイルシステムのメリットは、ただ単にデータを保護するだけでなく、ファイルシステム全体が保護できることにあります。ジャーナリングの目的は、「メタ・データ」(スーパーブロックやiノードテーブル、iノードテーブルからリンクされているデータなど)の整合性をとることにあります。 ジャーナリングファイルシステムでは、ジャーナルの変更記録のみを確認するので、ファイルシステムの整合性のチェックが非常に短時間で行え、また整合性が取れた状態に復帰するのも短時間で済みます。
- この記事 (ジャーナリングファイルシステム 【journaling file system】) も参考になった。
通常のファイルシステムでは、ファイルを書き込んだり書き換えたりする際、ファイルシステムの管理領域(メタデータ)の内容を変更している最中に不意の電源断などのトラブルが生じると、管理領域の内容に矛盾が生じ、データへの参照が失われたり、復旧に膨大な時間がかかる場合がある。 ジャーナリングファイルシステムではいきなり管理情報(メタデータ)を書き換えるのではなく、一旦これから行う変更をジャーナルと呼ばれる特殊な領域に時系列で保存し、それから管理情報の書き換えを行う。操作中に障害が発生しても、ジャーナルの内容を参照すれば即座に変更の破棄あるいは復旧を行うことができ、管理領域の一貫性を保ちつづけることができる。 データベース管理システム(DBMS)のトランザクション処理などに類似しているが、あくまで管理領域のみを保護する機構であり、ファイルの内容(データ本体)の保全は行わないため、データの喪失を防ぐには他の仕組みを併用する必要がある。
- いきなりディスクに書き込みを行うのではなく、ジャーナリングを介してディスクに書き込みを行う。自分の解釈としては、ディスク書き込み時に障害が発生した状況におけるにファイルシステムの整合性を保つためのレイヤーである。ジャーナリングによって、障害後に書き込み対象の複数のデータブロックが書き込まれる or 書き込まれないの 2 通りの状態に制限することができる。(キーワード : 整合性と復旧が可能)
inode に関して
- inode とはファイルシステムで使われているデータ構造のことである。
cat haytok.txtをするまでの流れを i ノードを交えて説明する。- ディレクトリエントリから
haytok.txtに該当する inode 番号を取得する。 - inode 番号をもとに第二パーティションの 3 つ目のセクタの inode テーブルから該当する inode を取り出す。
- 取り出した inode に含まれるファイルデータを保持したデータブロックへのポインタによりファイルデータを持つデータブロックが特定できる。(ブロック番号がわかる。)
- ディスク領域で取得したブロック番号が指す箇所を参照して、最終的な実態を出力する。
- ディレクトリエントリから
- inode に関連したこの記事 (inodeから見たmvやcpの動き) が非常に面白かった。
この記事 (MySQLのbinlogとredo logについて) ログ周りの機能を確認した。
- redo log に関して
- redo log とは InnoDB におけるログのことで、更新データの一時保存やクラッシュ時におけるデータの復元などのようとで使用される。直接ディスクに書き込むような実装にすると、ディスクアクセスに時間がかかるため、InnoDB エンジンがメモリ上でレコードを更新し、redo log buffer に記録すると、レコードの更新操作が完了したとみなす。
- redo log のファイルサイズは固定なので、最後のファイルが満帆になった時は最初のファイルに戻って書き込みが行われる。
- binlog に関して
- データベースの復元やレプリケーションに利用される。
- undo log に関して
- ?
- 記事に記載されていた以下の文言はほんまに正しいんか??? OS レベルの話も関連してくるのできちんとした調査がいる。
2.Page cache。ファイルシステムのCache(メモリ)に存在します。writeシステムコールの呼び出しでデータをPage Cacheに書き出します。 3.Hard Disk。ハードディスクに存在します。fsyncシステムコールを呼び出して、データをHard Diskに保存します
- redo log に関して
ここでやっと元の記事 (1. ファイルシステムについてざっくり理解する) の内容に戻ることができる。
以下の文言がファイルシステムを端的に表現されていた。
ファイルシステムの主な仕事は、まさにその、ディスク上のどこになにが置いてあるかを記録しておき、アプリケーションの要求に応じてデータを読み出す、もしくは書き込む、ということになります。
ユーザ空間からカーネル空間にコンテキストがスイッチする際の処理の移り変わりの表現が参考になった。カーネル上でメモリを確保あるいは解放する際の関数に kmalloc / kfree あった記憶があるので、そんな感じの処理を行なってユーザー空間からページキャッシュと呼ばれるカーネル空間内のメモリ用域にデータをコピーする。
write システムコールによって、処理のコンテキストがカーネル空間に切り替わると、まず始めに、ページキャッシュと呼ばれるカーネル空間内のメモリ領域に、アプリケーションが書き込みをリクエストしている引数 buf で指定されたデータをコピーします。この処理は、図中番号2の部分にあたります。
細かいメモは、手元のノートにまとめた … 文字だけで表現するのは厳しい … 気が向いたらノートを画像に吐き出す。
次に、この記事 (2. ファイルシステムのメタデータについて) を読んでファイルシステムのメタデータと inode に関して調査をした。
ポイントは、分割して書き込まれたバッファがどのディスクに書き込まれたの情報を保持する役割を果たすのがメタデータである。
細かいメモは、手元のノートにまとめた … 文字だけで表現するのは厳しい … 気が向いたらノートを画像に吐き出す。
最後に、この記事 (3. fsync はなぜ時間がかかるのか) を読んで fsync システムコールやジャーナリングに関して調査をした。
fsync システムコールは write システムコールと比較してかなり遅い。(機能が異なるので比較する意味はないが、数百倍オーダーで変わる。)
write システムコールは主にユーザー空間からカーネル空間へのメモリのコピーなので、それほど時間がかからない。
一方、fsync システムコールはリターンする時点でファイルの永続性を保証するために、ディスクへの書き込みの処理が完了するまでに待機する時間がかかる。
デバドラから来たデータはまずストレージ内部の揮発性メモリでできたキャッシュに置かれる。ストレージデバイスは任意のタイミングで適宜、永続的なデータの保存領域へ移動させる。
ソフトウェア側には、HDD や SSD にはデバイスにおけるキャッシュ上のデータを永続的な保存領域へ移動させることを明示的に行うフラッシュコマンドを利用することができる。ただ、このフラッシュには時間がかかる。理由は、ジャーナリングなどが行われているからである。
fsync の内部では、ディスクへの書き込み最中にシステムがクラッシュしてもメタデータの整合性が担保できるような書き込み方法を実装しています。
一般的に、データの整合性を担保する書き込み手法として、ジャーナリングもしくは、ファイルシステムのディスク上のレイアウトをログ構造にする、という2通りの方法が用いられています。
それらの仕組みでは、一つのデータをディスクに書き込むだけで、ストレージデバイス上のキャッシュのフラッシュリクエストを複数回発行する必要があり、そのフラッシュリクエストが fsync に時間がかかる主な要因になっています。
メモリから直にストレージデバイスに対して買い込んでいる最中にクラッシュすると、データの整合性が保てなくなる。この整合性を保つためにジャーナルログが使用される。これにより、書き込まれる or 書き込まれないの 2 通りの状態のみに制限することができる。
以下の文言が一番重要である。
来の書き込みたかった場所へデータ書き込むのは、必ず、対応するジャーナル領域のデータが、ストレージデバイスのキャッシュから、永続領域へ移動された後である必要があります。
この書き込みの制御を行うためにフラッシュコマンドが活用される。
結論、fsync システムコール内部では何度もフラッシュが実現されるので処理に時間がかかってしまう。
きちんと理解しようとすると、この記事に加えて論文を読む必要があある。
書き込みバリアに関してはこの記事 (第22章 書き込みバリア) が参考になった。
MySQL の MVCC と InnoDB に関する記事 (MVCCとInnoDBでの実装について)
複数の trx が存在するときにお互いの操作がどのように影響を与え合うかは分離性 (Isolation) が関係してくる。
悲観ロック
シングルスレッドとマルチスレッド
そこでこれらの問題を解決するのが MVCC である。
MySQL における MVCC の挙動を確認する。
- Snapchot Isolaton という手法で実装されている。
purge thread によって定期的にガーベジコレクションが削除される。
クラスタインデックス
セカンダリインデックス
カバリングインデックス
YouTube の動画
- Yanagisawa-san の MyNA会での YouToube 上の発表 が異常にわかりやすくて感動した :)
- アクティブトランザクションとはまだ commit or rollback されていないトランザクションのことである。(参考 : 10 トランザクション)
InnoDB における MVCC のガベージコレクションに関する記事 InnoDBのMVCCのガベージコレクションについて を読んで学んだことを教えてください。
この記事に関する発表が YouTube にもあった。
標準のトランザクションレベルは REPEATABLE READ である。
MVCC を実現するには、trx 毎のスナップショットなどのための追加のデータ領域が必要となる。適度なタイミングで古いバージョンのトランザクションを削除する必要がある。タイミングとしては、そのスナップショットを見ている trx が完了すれば誰もアクセスしなくなるので、それ以降が削除のタイミングとなる。
誰からも参照されない undo log は purge の対象となる。
参考に記事に関する発表動画があったのでそれも見て勉強してみた。
- 動画自体は少し難しくて、理解できない箇所が多かった。もっと知識をつけたい。
- スナップショットのためのデータ領域が必要となる。
- 定期的にスナップショットを削除する必要がある。
- スナップショットのデータ構造の解説
- clustered index では、削除に関しては delete のフラグだけが立つ。
- レコードの更新の際、過去の履歴は undo log で持つ。
- secondary index に関連するカラムが更新された時、違う場所のデータがないといけない。update の時は古いバージョン (削除フ ラグを立てる。) と新しいバージョンの leaf が存在しないといけない。
- undo log は rollback segment に保管されている。
- undo log の purge のタイミングは、その undo log を作った trx の後の trx しかできない。
- history list
- commit された undo log
- purge の大まかな流れ
- history length によって purge が行われるかを判定する。
WAL がディスクに吐き出されるタイミングについて教えてください。
ポスグレに関して
trx のコミット時である。
第 25章ログ先行書き込み (WAL) に以下の記述があった。
WALを採用する1つ目の明白な利点はディスクへの書き込み回数が大幅に減ることです。 というのは、トランザクションコミットの時にそのトランザクションで変更された全てのデータファイルではなく、ログファイルだけをディスクに吐き出せばよいからです。
DB スペシャリストの過去問も参考になった。
システム障害発生時には,データベースの整合性を保ち,かつ,最新のデータベース状態に復旧する必要がある。このために,DBMSがトランザクションのコミット処理完了とみなすタイミングとして,適切なものはどれか。 ログファイルへのコミット情報書込み完了時点
ほんまに正しいかが自信ない。最終的にはソースコードを読んだ方が早そう。(ソースコードリーディングにおけるネタの 1 つではある。)
この記事 (ジャーナリングファイルシステムが保護する「情報」- データベースでのトランザクション管理) 的にもコミット時にはジャーナルログが残っているとあるから、commit 済みであれば redo log や WAL から復元可能?
BTree と B+Tree と InnoDB のインデックスに関して教えてください。(
- この記事 (【MySQL】InnoDBのインデックス) が非常に参考になった。
| - | BTree | B+Tree |
|---|---|---|
| 歴史 | - | BTree の派生系 |
| データの格納場所 | ルートノード、インターナルノード、リーフノード | リーフノード (末端) |
| 特徴 | - | リーフノード以外のノード (ルートノード、インターナルノード) にはキーを格納する。 |
| 特徴 | - | リーフノードの隣接間はポインタで相互接続される。 |
| 特徴 | - | 等価検索の処理時間が短縮され、特に範囲検索が高速なので Database のインデックスに活用されている。 |
| 検索時間 | O(log n) | O(log n) |
InnoDB のインデックスには B+Tree が利用されている。
インデックスの種類は以下である。
- クラスタインデックス
- プライマリキーがクラスタのインデックスとなり、検索が行われる。
- セカンダリインデックスでデータが見つからなかった時は、セカンダリインデックスから渡される主キーでクラスタインデックスにアクセスしてデータを取得する。
- セカンダリインデックス
- 特定のカラム (主キーやユニークキー以外) に対してつけるインデックスのことである。セカンダリインデックスの B+Tree のリーフノードには主キーとインデックスが貼られたカラムが保持される。
- カバリングインデックス
- インデックスをもとに検索する際に、セカンダリインデックスに取得したいデータがある時は、そこで検索が終了する。この状態のことをカバリングインデックスと呼ぶ。
- 複数インデックス
- 複数のカラムに対してインデックスを持たせる。インデックスを付与したカラムを where 句に指定して検索をすると、高速な検索が可能となる。
あるカラムに index を貼ると、それ専用の B+Tree が作成される。